






numpy实现RNN层的前向传播和反向传播
numpy实现的RNN前向输出和反向传播的梯度都可以和pytorch对齐
总共实现了这几个层:
numpy实现RNN层的前向传播和反向传播 - 知乎 (zhihu.com)
numpy实现embedding层的前向传播和反向传播 - 知乎 (zhihu.com)
numpy实现LSTM层的前向传播和反向传播 - 知乎 (zhihu.com)
损失函数的前向传播和反向传播 - 知乎 (zhihu.com)
全连接层的前向传播和反向传播 - 知乎 (zhihu.com)
Introduction
RNN是个循环神经网络,包括隐藏层和输入层,所以输入有两个,一个是用户显示提供的输入,另一个是上一个时刻神经网络隐藏层的输出,按照时间轴展开的话,RNN是同一个没有其他的构造
循环神经网络,也就是只有一个神经unit,每次输入一个时刻的数据,直到当前所有时刻的数据全部输入完毕,才会输入下一个sequence句子,对每个sequence都是一次输入一个时刻。
rnn的输入的格式是(sequence_length, batchsize, embed_dim),sequence_length放在最开始的目的主要是考虑到输入是按照时间轴进行的
这要特别注意,输入的时候,是按照时刻输入的
隐藏层的输出可以做分类,做predict,pytorch对应的就是RNNCell,只输出隐藏层
RNN的计算公式是 y = ( W i h ⋅ I + W h h ⋅ H i + b i a s ) , H i + 1 = t a n h ( y ) y=(W_{ih}\cdot I+W_{hh}\cdot H_i+bias),H_{i+1}=tanh(y) y=(Wih⋅I+Whh⋅Hi+bias),Hi+1=tanh(y)
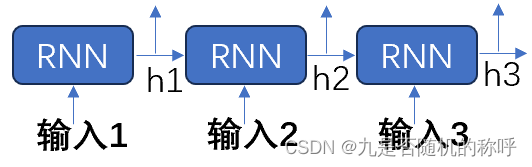
下图虽然通过时间轴展开有多个rnn,但是其实是同一个rnncell,只是时间点不相同,也就是输入一个句子,但是每次都只有一个单词输入进去,像输入"I can finish the thing.",这几个单词每次只输入一个,输入应该依次是[I, can, finish, the, thing],RNN只有参数会update,实际运算是相同的。
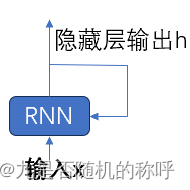
RNNCell
RNNCell — PyTorch 2.0 documentation
pytorch实现了两个RNN,一个是RNNCell仅仅只输出隐藏层,每次输入都是一个时刻,也就是(batch, embed_dim),沿着时间轴不断地输入,直到sequence_length输出完毕的,下面的example就是的
最开始的隐藏层是没有输出的,所以初始化的隐藏层是随机的或者全0
根据计算公式 y = ( W i h ⋅ I + W h h ⋅ H i + b i a s ) , H i + 1 = t a n h ( y ) y=(W_{ih}\cdot I+W_{hh}\cdot H_i+bias),H_{i+1}=tanh(y) y=(Wih⋅I+Whh⋅Hi+bias),Hi+1=tanh(y)
拿到的就是H_i+1,每个时刻都有隐藏层输出,这样的方式使用起来更加方便,可以根据自己的需要,来实现不同的网络结构,用起来更加舒服。
用numpy实现的也是这个,下面的RNN可以用rnncell来实现
rnn = nn.RNNCell(10, 20) #输入embed_dim=10,hidden_dim = 20
input = torch.randn(6, 3, 10) #(sequence_length=6, batchsize=3, embed_dim=10)
hx = torch.randn(3, 20) #(batchsize=3, hidden_dim = 20)
output = []
for i in range(6): # sequence_length=6
hx = rnn(input[i], hx) #hx=(batchsize, hidden_dim) input[i]=(batchsize, embed_dim)
output.append(hx)
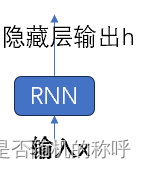
RNN
RNN — PyTorch 2.0 documentation
另一个RNN可以有多层rnncell,输出是最后一个时刻输出的隐藏层,以及每一个时刻所有的输出的concat
尽管有多层RNN,但是每个时刻最后一层输出都是(batchsize, hidden_dim),所有时刻都concat起来以后就是output(sequence_length=5, batchsize=3, hidden_dim=20)
最后一个时刻输出的隐藏层有好几层
所以下面这个example的输出,output就是所有时刻最后一个隐藏层的输出的concat,对应最上面的方框
hn就是最后一个时刻所有隐藏层的输出的concat,对应最右侧的方框。
这样的方式就显得太固定了,不能自由构造网络
rnn = nn.RNN(10, 20, 2) #输入embed_dim=10,hidden_dim = 20 layer=2
input = torch.randn(5, 3, 10) #(sequence_length=5, batchsize=3, embed_dim=10)
h0 = torch.randn(2, 3, 20) #(layer=2, batchsize=3, hidden_dim =20)
output, hn = rnn(input, h0) #output(sequence_length=5, batchsize=3, hidden_dim=20) hn(layer=2, batchsize=3, hidden_dim=20)
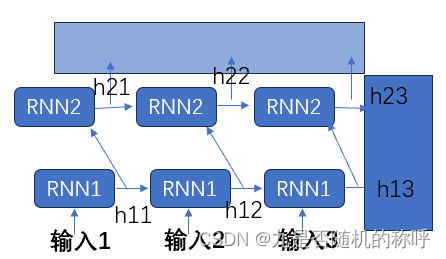
前向传播运算
每一个rnncell前向传播使用的运算公式是:
y
=
(
W
i
h
⋅
I
+
W
h
h
⋅
H
i
+
b
i
a
s
)
,
H
i
+
1
=
t
a
n
h
(
y
)
y=(W_{ih}\cdot I+W_{hh}\cdot H_i+bias),H_{i+1}=tanh(y)
y=(Wih⋅I+Whh⋅Hi+bias),Hi+1=tanh(y)
但实际的话,torch.nn.RNNCell是存在两个bias,所以实现的是
y = ( W i h ⋅ I + W h h ⋅ H i + b i a s i h + b i a s h h ) , H i + 1 = t a n h ( y ) y=(W_{ih}\cdot I+W_{hh}\cdot H_i+bias_{ih}+bias_{hh}),\\ H_{i+1}=tanh(y) y=(Wih⋅I+Whh⋅Hi+biasih+biashh),Hi+1=tanh(y)
def forward(self, inputs, hidden0):
self.z_t = np.matmul(inputs, self.inputs_params) + np.matmul(hidden0, self.hidden_params)
self.h_t_1 = np.tanh(self.z_t + self.bias_ih_params + self.bias_hh_params)
return self.h_t_1
反向传播运算
根据前向传播,从后往前推导即可,首先是tanh函数 t a n h ( x ) = e x − e − x e x + e − x tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} tanh(x)=ex+e−xex−e−x
t a n h ( x ) ′ = ( e x + e − x ) 2 − ( e x − e − x ) 2 ( e x + e − x ) 2 = 4 ( e x + e − x ) 2 = 1 − ( t a n ( x ) ) 2 tanh(x)'=\frac{(e^x+e^{-x})^2-(e^x-e^{-x})^2}{(e^x+e^{-x})^2}=\frac{4}{(e^x+e^{-x})^2}=1-(tan(x))^2 tanh(x)′=(ex+e−x)2(ex+e−x)2−(ex−e−x)2=(ex+e−x)24=1−(tan(x))2
即 y = t a n h ( x ) , y ′ = 1 − y 2 y = tanh(x), ~~~~~~~~~~y' = 1-y^2 y=tanh(x), y′=1−y2
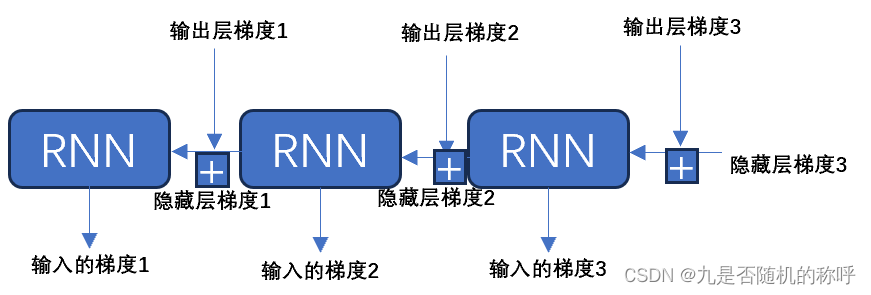
前向传播是按照sequence的顺序依次向前传播,所以反向传播要反着来,从后向前传播梯度
上面的图是前向传播从左到右,这的话反着来从右到左反向传播,隐藏层梯度输入最开始是没有数值的,初始化0,所以隐藏层梯度3=0,输出层梯度3、2、1是反向传播过来的,可能是分类网络“full connect + softmax+cross entropy”传过来的梯度
RNN实际传播过来的**“该时刻隐藏层梯度”= 该时刻输出层梯度 + 下一时刻隐藏层梯度**,reason是输出层运算用的是隐藏层的输出h,下一时刻的rnn运算也是用的隐藏层的输出h,所以rnn实际传播过来的该时刻隐藏层梯度要相加。即 Δ h i = Δ o u t i + Δ h i + 1 \Delta h_i = \Delta out_i + \Delta h_{i+1} Δhi=Δouti+Δhi+1 ,最开始反向传播用的隐藏层梯度 Δ h s e q u e n c e _ l e n g t h + 1 = 0 \Delta h_{sequence\_length+1}=0 Δhsequence_length+1=0 。
每个时刻的RNN反向传播运算,要求出“上一个时刻的隐藏层梯度”
Δ
h
i
−
1
\Delta h_{i-1}
Δhi−1 和“该时刻的输入梯度”
Δ
I
n
i
\Delta In_i
ΔIni
def backward(self, delta, hidden_delta, inputs, hidden0, h_t_1):
delta += hidden_delta # 该时刻隐藏层梯度 = 该时刻输出传过来的梯度 + 下一时刻隐藏层的梯度
d_z_t = delta * (1 - h_t_1**2) # 求出tanh函数内输入的梯度
input_delta = np.matmul(d_z_t, self.inputs_params.T) #求出该时刻输入的梯度
self.inputs_params_delta += np.matmul(d_z_t.T, inputs).T #求出输入矩阵W_ih参数的梯度
hidden_delta = np.matmul(d_z_t, self.hidden_params.T) #求出上一时刻隐藏层的梯度
self.hidden_params_delta += np.matmul(d_z_t.T, hidden0).T #隐藏层矩阵W_hh参数的梯度
self.bias_ih_delta += np.sum(d_z_t, axis=(0)) #输入bias_ih的梯度
self.bias_hh_delta += np.sum(d_z_t, axis=(0)) #隐藏层bias_hh的梯度
return input_delta, hidden_delta #返回输入的梯度,上一时刻隐藏层梯度
以上函数传过来的参数,含义是delta该时刻输出传过来的梯度,hidden_delta:下一时刻隐藏层的梯度,inputs该时刻的输入,h_t_1该时刻隐藏层输出
前向传播就是:self.z_t = np.matmul(inputs, self.inputs_params) + np.matmul(hidden0, self.hidden_params)
也就是矩阵运算,矩阵运算求梯度可以见full connect的推导:全连接层的前向传播和反向传播 - 知乎 (zhihu.com)
总之矩阵运算求导,像:out = np.matmul(In, ip)
Δ I n = n p . m a t m u l ( o u t , i p T ) \Delta In = np.matmul(out, ip^T) ΔIn=np.matmul(out,ipT) , Δ i p = n p . m a t m u l ( o u t T , I n ) T = n p . m a t m u l ( I n T , o u t ) \Delta ip = np.matmul(out^T, In)^T=np.matmul(In^T, out) Δip=np.matmul(outT,In)T=np.matmul(InT,out)
参数初始化
所有参数都是使用均匀分布进行初始化,均匀分布的区间是 U ( − 1 h i d d e n _ s i z e , 1 h i d d e n _ s i z e ) U(-\sqrt{\frac{1}{hidden\_size}}, \sqrt{\frac{1}{hidden\_size}}) U(−hidden_size1,hidden_size1)
参数update
使用反向传播得到的参数的梯度,对参数update
def update(self, lr=1e-10):
if self.bias:
self.bias_ih_params -= lr * self.bias_ih_delta[np.newaxis, :]
self.bias_hh_params -= lr * self.bias_hh_delta[np.newaxis, :]
self.inputs_params -= lr * self.inputs_params_delta
self.hidden_params -= lr * self.hidden_params_delta
参数梯度置0
参数update以后,参数的梯度要置0,方便下次累加梯度使用
def setzero(self):
self.inputs_params_delta[...] = 0
self.hidden_params_delta[...] = 0
if self.bias:
self.bias_ih_delta[...] = 0
self.bias_hh_delta[...] = 0
多层RNN
多层RNN,第二层以后的输入都是前一层的输出,即
l a y e r 1 _ H i + 1 = t a n h ( W i h ⋅ I + W h h ⋅ l a y e r 1 _ H i + b i a s ) l a y e r 2 _ H i + 1 = t a n h ( W i h ⋅ l a y e r 1 _ H i + 1 + W h h ⋅ l a y e r 2 _ H i + 1 + b i a s ) . . . layer1\_H_{i+1}=tanh(W_{ih}\cdot I+W_{hh}\cdot layer1\_H_i+bias) \\ layer2\_H_{i+1}=tanh(W_{ih}\cdot layer1\_H_{i+1}+W_{hh}\cdot layer2\_H_{i+1}+bias)\\ ... layer1_Hi+1=tanh(Wih⋅I+Whh⋅layer1_Hi+bias)layer2_Hi+1=tanh(Wih⋅layer1_Hi+1+Whh⋅layer2_Hi+1+bias)...
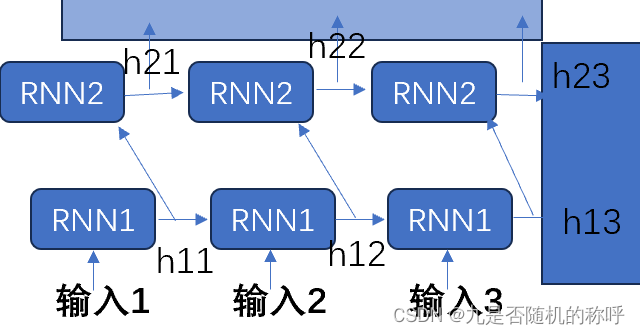
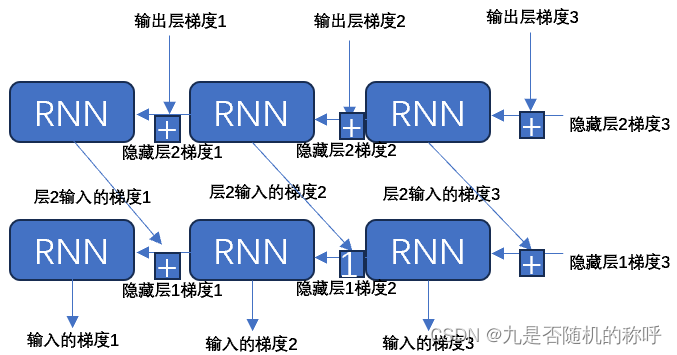
前向传播依次计算即可,可以通过使用rnncell来构造,反向传播也可以使用rnncell来构造,此时反向传播还是相同的,先拿到该时刻输出层的梯度以及下一个时刻隐藏层梯度,然后求出顶层输入梯度和顶层上个时刻隐藏层梯度
像两层RNN,前向上面已经给出来了,反向还是相同的,区别主要是前面的层,该时刻输入的梯度是从后面传过来的,而不是输出的梯度了,只有最上面的那层输入的梯度是输出直接传过来的。
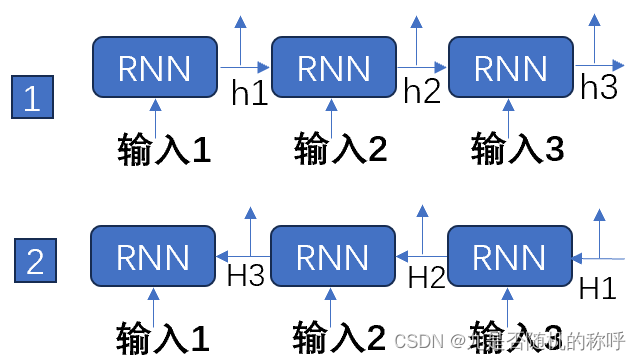
双向bidirectional RNN
双向RNN,也就是两个方向运算,RNN还是相同的不变,也就是给定一个输入sequence,像输入[1, 2, 3, 4, 5, 6],正向是[1,2, 3,4,5,6]能得到一个输出[h1, h2, h3,h4,h5,h6],反向是[6,5,4,3,2,1],也能得到一个输出[H1, H2, H3, H4, H5, H6],然后concat[h1+H6, h2+H5, h3+H4, h4+H3, h5+H2, h6+H1]就能得到完整的输出
所以双向其实就是RNN正向和反向都拿到隐藏层的输出,然后拼起来就得到最后的隐藏层输出
反向传播的话,也需要传播两次,反向和正向传播即可,梯度累加起来,最后再进行update
Example:这个是双向RNN网络
有RNN,输入,
字符RNN
在这使用写好的RNN进行了实践,输出的效果还可以的,使用了26个英文字母做字符的predict训练,使用了26个英文字母的,然后train的时候,是给定sequence=10,每次拿10个字符,然后label往后移动一个字符
输入是:inputs_character = "abcdefghijklmnopqrstuvwxyz abcdefghijklmnopqrstuvwxyz "
train以后使用保存的模型predict,输入“c”,就能得到相应的输出“defghijklmnopqrst”
然后还使用字符训练了诗词,数据是来自:Werneror/Poetry: 非常全的古诗词数据,收录了从先秦到现代的共计85万余首古诗词。 (github.com)
最开始用的字符级别产生,one-hot字向量,发现不能收敛,loss一直不下降的呢,而且train速度很慢的呢,然后使用了embedding层,numpy实现embedding层的前向传播和反向传播
使用embedding以后训练速度好了很多的,但不管是rnn或者是使用lstm,都不能收敛的,考虑到没有对词频进行statistic,导致了long tail分布,对词频进行statistic排序然后拿前多少个词频,也就是拿到排在前面的词频,后面的词频较小的词,包括小词频的句子所在行都被删除了,所以训练集只包括词频在前的句子,若是直接训练,会发现训练很难收敛,主要是词频太小的句子,训练次数太少,不能收敛的,而且词频小的词还挺多的,导致了不能收敛
statistic词频以后然后删掉低频词所在的句子,训练以后就可以正常收敛了。但是输出的句子没有句意,虽说可以输出了。
输入和输出的:残星落檐外
残月江花来,
山明水开不。
色月山无知,
花明中限处。
诗句RNN
Werneror/Poetry: 非常全的古诗词数据,收录了从先秦到现代的共计85万余首古诗词。 (github.com)
字符的train发现输出不太好,字和字之间没有relation,输出完全没有句子意思,使用hanlp分词以后效果才变好的,hanlp分词使用的是这个模型-FINE_ELECTRA_SMALL_ZH,细腻度分词的。拿到了每句对应的分词,以及id2char,char2id的dictionary
train的时候发现输出的很多都是EOS符号,EOS也就是结束符号的,主要是填充的时候使用了很多的EOS符号,所以train梯度不太对了,这边对梯度进行了缩放,EOS的梯度*0.001,EOS的梯度缩小了1000倍。就可以正常训练了的,loss也正常下降的,使用了RNN和LSTM训练,RNN训练算正常的。
这边给出几个Example:
输入:暮云千山雪
暮云千山雪,
春行复深上。
风无流鸟树,
清客鸟归还。
输入:朝送山僧去
朝送山僧去,
莫君在梦何。
不知山不知,
山中我欲幸。
输入:携杖溪边听
携杖溪边听,
抱我树月知。
故山中常更,
鸟中应上鬓。
输入:楼高秋易寒
楼高秋易寒,
凭谁暮云云,
添我下来衣,
知一别来云,
输入:残星落檐外
残星落檐外,
馀月罢窗来,
水白先成秋,
霞暗未成不,
输入:月在画楼西
月在画楼西,
烛故是愁来。
何转知此山,
花常更花中。
numpy实现的codes
还实现了单层train的codes,需要的话可以打开注释train_single()
import numpy as np
import torch
from torch import nn
from copy import deepcopy
def torch_compare_rnn(input_size, delta, hidden_size, bias, inputs, inputs_params, hidden_params, bias_ih_params, bias_hh_params):
network = nn.RNNCell(input_size=input_size, hidden_size=hidden_size, bias=bias).requires_grad_(True)
network.double()
cnt = 0
for i in network.parameters():
if cnt==0:
i.data = torch.from_numpy(inputs_params)
i.retain_grad = True
elif cnt==1:
i.data = torch.from_numpy(hidden_params)
i.retain_grad = True
elif cnt==2:
i.data = torch.from_numpy(bias_ih_params)
i.retain_grad = True
else:
i.data = torch.from_numpy(bias_hh_params)
i.retain_grad = True
cnt += 1
inputs = torch.tensor(inputs, requires_grad=True, dtype=torch.float64)
output = network(inputs)
delta = torch.tensor(delta)
output.backward(delta)
# sum = torch.sum(output) # make sure the gradient is 1
# kk = sum.backward()
grad_inputs_params = 0
grad_hidden_params = 0
grad_bias_ih = 0
grad_bias_hh = 0
cnt = 0
for i in network.parameters():
if cnt==0:
grad_inputs_params = i.grad
elif cnt==1:
grad_hidden_params = i.grad
elif cnt==2:
grad_bias_ih = i.grad
else:
grad_bias_hh = i.grad
cnt += 1
inputs.retain_grad()
output.retain_grad()
k = inputs.grad
return output, k, grad_inputs_params, grad_hidden_params, grad_bias_ih, grad_bias_hh
class rnncell_layer(object):
def __init__(self, input_size, hidden_size, bias, inputs_params=[], hidden_params=[], bias_ih_params=[], bias_hh_params=[]):
self.input_size = input_size
self.hidden_size = hidden_size
self.bias = bias
if bias and list(bias_ih_params)!=[]:
self.bias_ih_params = bias_ih_params[np.newaxis, :]
elif bias:
ranges = np.sqrt(1 / hidden_size)
self.bias_ih_params = np.random.uniform(-ranges, ranges, (hidden_size))[np.newaxis, :]
if bias and list(bias_hh_params)!=[]:
self.bias_hh_params = bias_hh_params[np.newaxis, :]
elif bias:
ranges = np.sqrt(1 / hidden_size)
self.bias_hh_params = np.random.uniform(-ranges, ranges, (hidden_size))[np.newaxis, :]
if list(inputs_params)!=[]:
self.inputs_params = inputs_params
else:
ranges = np.sqrt(1 / (hidden_size))
self.inputs_params = np.random.uniform(-ranges, ranges, (input_size, hidden_size))
if list(hidden_params)!=[]:
self.hidden_params = hidden_params
else:
ranges = np.sqrt(1 / (hidden_size))
self.hidden_params = np.random.uniform(-ranges, ranges, (hidden_size, hidden_size))
self.inputs_params_delta = np.zeros((input_size, hidden_size)).astype(np.float64)
self.hidden_params_delta = np.zeros((hidden_size, hidden_size)).astype(np.float64)
self.bias_ih_delta = np.zeros(hidden_size).astype(np.float64)
self.bias_hh_delta = np.zeros(hidden_size).astype(np.float64)
def forward(self, inputs, hidden0):
self.z_t = np.matmul(inputs, self.inputs_params) + np.matmul(hidden0, self.hidden_params)
self.h_t_1 = np.tanh(self.z_t + self.bias_ih_params + self.bias_hh_params)
# self.h_t_1 = self.z_t + self.bias_ih_params + self.bias_hh_params
return self.h_t_1
def backward(self, delta, hidden_delta, inputs, hidden0, h_t_1):
# previous layer delta
delta += hidden_delta
d_z_t = delta * (1 - h_t_1**2)
input_delta = np.matmul(d_z_t, self.inputs_params.T)
self.inputs_params_delta += np.matmul(d_z_t.T, inputs).T
hidden_delta = np.matmul(d_z_t, self.hidden_params.T)
self.hidden_params_delta += np.matmul(d_z_t.T, hidden0).T
self.bias_ih_delta += np.sum(d_z_t, axis=(0))
self.bias_hh_delta += np.sum(d_z_t, axis=(0))
return input_delta, hidden_delta
def setzero(self):
self.inputs_params_delta[...] = 0
self.hidden_params_delta[...] = 0
if self.bias:
self.bias_ih_delta[...] = 0
self.bias_hh_delta[...] = 0
def update(self, lr=1e-10):
self.inputs_params_delta = np.clip(self.inputs_params_delta, -6, 6)
self.hidden_params_delta = np.clip(self.hidden_params_delta, -6, 6)
if self.bias:
self.bias_ih_delta = np.clip(self.bias_ih_delta, -6, 6)
self.bias_hh_delta = np.clip(self.bias_hh_delta, -6, 6)
self.bias_ih_params -= lr * self.bias_ih_delta[np.newaxis, :]
self.bias_hh_params -= lr * self.bias_hh_delta[np.newaxis, :]
self.inputs_params -= lr * self.inputs_params_delta
self.hidden_params -= lr * self.hidden_params_delta
def save_model(self):
return [self.inputs_params.astype(np.float32), \
self.hidden_params.astype(np.float32), \
self.bias_ih_params.astype(np.float32), \
self.bias_hh_params.astype(np.float32)]
def restore_model(self, models):
self.inputs_params = models[0]
self.hidden_params = models[1]
self.bias_ih_params = models[2]
self.bias_hh_params = models[3]
def train_single():
input_size = 100
hidden_size = 900
batch_size = 100
bias = True
inputs = np.random.randn(batch_size, input_size)
inputs_params = np.random.rand(input_size, hidden_size) / np.sqrt(input_size/2)
hidden_params = np.random.rand(hidden_size, hidden_size) / np.sqrt(hidden_size/2)
if bias:
bias_ih_params = np.random.rand(hidden_size) / np.sqrt(hidden_size/2)
bias_hh_params = np.random.rand(hidden_size) / np.sqrt(hidden_size/2)
else:
bias_ih_params = []
bias_hh_params = []
hidden_0 = np.random.rand(batch_size, hidden_size)
hidden_delta = np.zeros((batch_size, hidden_size))
rnncell = rnncell_layer(input_size, hidden_size, bias, inputs_params, hidden_params, bias_ih_params, bias_hh_params)
outputs = np.random.rand(batch_size, hidden_size)
# output = rnncell.forward(inputs, hidden_0)
# delta = np.ones((batch_size, hidden_size)).astype(np.float64)
# partial, hidden_delta = rnncell.backward(delta.T, hidden_delta.T, inputs.T, hidden_0.T)
for i in range(3000):
out = rnncell.forward(inputs, hidden_0)
sum = np.sum((outputs - out) * (outputs - out))
delta = 2*(out - outputs)
partial, _ = rnncell.backward(delta, hidden_delta, inputs, hidden_0, outputs)
rnncell.update(0.0001)
rnncell.setzero()
# out = convolution.forward(inputs)
# sum = np.sum((outputs - out) * (outputs - out))
# delta = 2*(out - outputs)
# partial_, = convolution.backward_common(delta)
# partial = convolution.backward(delta, 0.0001)
print(sum)
if __name__=="__main__":
#https://blog.csdn.net/SHU15121856/article/details/104387209
#https://gist.github.com/karpathy/d4dee566867f8291f086
#https://github.com/JY-Yoon/RNN-Implementation-using-NumPy/blob/master/RNN%20Implementation%20using%20NumPy.ipynb
#https://stackoverflow.com/questions/47868265/what-is-the-difference-between-an-embedding-layer-and-a-dense-layer
#https://towardsdatascience.com/deep-learning-4-embedding-layers-f9a02d55ac12
#https://discuss.pytorch.org/t/how-nn-embedding-trained/32533/5
# https://github.com/krocki/dnc/blob/master/rnn-numpy
# https://github.com/CaptainE/RNN-LSTM-in-numpy
# https://discuss.pytorch.org/t/what-is-num-layers-in-rnn-module/9843
# train_single()
input_size = 1000
hidden_size = 200
batch_size = 10
bias = True
inputs = np.random.randn(batch_size, input_size)
inputs_params = np.random.rand(input_size, hidden_size)
hidden_params = np.random.rand(hidden_size, hidden_size)
if bias:
bias_ih_params = np.random.rand(hidden_size)
bias_hh_params = np.random.rand(hidden_size)
else:
bias_ih_params = []
bias_hh_params = []
hidden_0 = np.zeros((batch_size, hidden_size))
hidden_delta = np.zeros((batch_size, hidden_size))
rnncell = rnncell_layer(input_size, hidden_size, bias, inputs_params, hidden_params, bias_ih_params, bias_hh_params)
output = rnncell.forward(inputs, hidden_0)
delta = np.ones((batch_size, hidden_size)).astype(np.float64)
partial, hidden_delta = rnncell.backward(delta, hidden_delta, inputs, hidden_0, output)
output_torch, partial_torch, grad_inputs_params, grad_hidden_params, grad_bias_ih, grad_bias_hh = torch_compare_rnn(input_size, delta, hidden_size, bias, inputs, inputs_params.T, hidden_params.T, bias_ih_params, bias_hh_params)
assert np.mean(np.abs(output - output_torch.cpu().detach().numpy())) < 1e-6, np.mean(np.abs(output - output_torch.cpu().detach().numpy()))
assert np.mean(np.abs(partial - partial_torch.cpu().detach().numpy())) < 1e-6, np.mean(np.abs(partial - partial_torch.cpu().detach().numpy()))
assert np.mean(np.abs(rnncell.inputs_params_delta.T - grad_inputs_params.cpu().detach().numpy())) < 1e-6, np.mean(np.abs(rnncell.inputs_params_delta.T - grad_inputs_params.cpu().detach().numpy()))
assert np.mean(np.abs(rnncell.hidden_params_delta.T - grad_hidden_params.cpu().detach().numpy())) < 1e-6, np.mean(np.abs(rnncell.hidden_params_delta.T - grad_hidden_params.cpu().detach().numpy()))
assert np.mean(np.abs(rnncell.bias_ih_delta - grad_bias_ih.cpu().detach().numpy())) < 1e-6, np.mean(np.abs(rnncell.bias_ih_delta - grad_bias_ih.cpu().detach().numpy()))
assert np.mean(np.abs(rnncell.bias_hh_delta - grad_bias_hh.cpu().detach().numpy())) < 1e-6, np.mean(np.abs(rnncell.bias_hh_delta - grad_bias_hh.cpu().detach().numpy()))
https://blog.csdn.net/SHU15121856/article/details/104387209
https://gist.github.com/karpathy/d4dee566867f8291f086
https://towardsdatascience.com/deep-learning-4-embedding-layers-f9a02d55ac12
https://discuss.pytorch.org/t/how-nn-embedding-trained/32533/5
https://github.com/krocki/dnc/blob/master/rnn-numpy
https://github.com/CaptainE/RNN-LSTM-in-numpy
https://discuss.pytorch.org/t/what-is-num-layers-in-rnn-module/9843



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











